Evo 2 | Changing Our Understanding of Life’s Code

NVIDIA and the Arc Institute have launched Evo 2, a 40-billion-parameter generative AI foundation model capable of analyzing and designing genetic sequences across all domains of life. Trained on nearly 9.3 trillion nucleotides from 128,000 species (including plants, animals, and microbes) Evo 2 represents the largest publicly available AI model for biological research to date. The model, now accessible via NVIDIA’s BioNeMo platform, promises to accelerate discoveries in healthcare and synthetic biology by predicting disease-causing mutations, simulating evolutionary processes, and generating synthetic genomes with yet unseen scale and precision.
The Language of Genomes
DNA is often compared to a blueprint for life, but a more apt comparison might be that of a language: each base letter (A, C, G, and T) contributes to a vast, intertwined text. Within this text, genes are like sentences encoding proteins, while punctuation marks—promoters, enhancers, introns, and other regulatory elements—govern how these sentences are read and interpreted. The grammar, however, is bewilderingly complex. Different organisms use similar letters and phrases in slightly different ways, from bacteria that have compact genomes to eukaryotes that carry dense layers of regulation and noncoding DNA.
Building an AI model that can read this language is an immense undertaking. Evo 2 does precisely this by training on over 9 trillion genomic letters gathered from across the tree of life. Despite the extraordinary diversity within these sequences (coding regions, noncoding regions, mobile genetic elements) it manages to synthesize an understanding of universal genomic rules that apply to organisms ranging from archaea to humans.

Evo 2 is trained on over 9.3 trillion nucleotides from over 128 thousand genomes across the three domains of life, visualized here as points clustered by similarity. (Credit: Arc Institute)
Why does that matter? Because most genomic discoveries involve pinpointing patterns, be they harmful mutations or beneficial traits. By drawing on data from so many forms of life, Evo 2 internalizes a broad “grammar” of how DNA works. This helps it detect, and even predict, changes with biological significance.
Evo 2’s Capabilities
Predicting the Effects of Mutations
The capacity to interpret mutations is a dream of precision medicine. Mutations sometimes have no effect, while other times they disrupt essential processes and lead to conditions like cancer or genetic disorders.
Traditionally, researchers have used sequence comparison and specialized models to guess how harmful a mutation might be. Yet these approaches typically rely on multiple-sequence alignments or human expert knowledge, which become limiting when dealing with rarer, noncoding changes or mutations in less-studied regions of the genome. It’s a process that can take months.
Evo 2 circumvents those bottlenecks, producing results in seconds. It works in a zero-shot manner meaning it requires no extra training on specific sets of disease-related mutations. It achieves this by evaluating how “likely” a particular variant is within the genome’s broader patterns. By comparing a mutated sequence against what it has learned from trillions of DNA bases, Evo 2 can then predict whether a change is suspiciously unnatural or relatively benign.
This ability extends beyond protein-coding genes into the sprawling world of noncoding DNA: long stretches of regulatory elements, regions that manage how genes are spliced, and even structural RNAs like tRNA or rRNA.
In clinical terms, that’s a major leap forward because noncoding regions, which make up most of our genome, remain poorly understood.
Tools such as Evo 2 may help close that gap by accurately flagging mutations that could alter gene regulation, potentially informing more precise diagnoses and personalized treatments.
Designing Entire Genomes
The generative nature of Evo 2 sets it apart from many other computational tools in genomics. It doesn’t just read; it can write. This involves producing new DNA sequences that not only follow the rules of biology but also exhibit authentic gene structures, regulatory motifs, and more.
Imagine you’re working on a microbe that produces a valuable enzyme for drug manufacturing. With conventional methods, designing a more efficient microbial genome is time-consuming and prone to guesswork. Evo 2 can streamline that process by generating a range of candidate genomes where the overall architecture—genes, promoters, regulatory elements—remains natural. The researcher then tests which design meets their specific needs.
Impressively, this generation can scale to entire bacterial or yeast chromosomes spanning hundreds of thousands to millions of base pairs. The result isn’t a random sequence of letters; it’s a carefully constructed genomic tapestry that includes genuine protein-coding genes, recognizable promoters, and “native-like” structural patterns. Although still a proof-of-concept, such capabilities hint at a future where engineers can custom-build microbes or synthetic life forms with tailored functions.
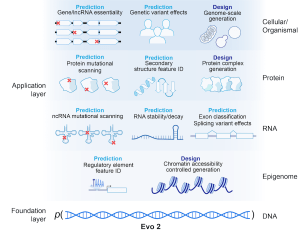
An overview of Evo 2’s capabilities across prediction and design tasks. (Credit: Arc Institute)
Steering DNA Design for Specific Goals
Genome-wide design needs more than pure generation. It requires control. Biological functionality isn’t just about genes; it also hinges on the complex interplay of epigenetic states such as chromatin accessibility.
In eukaryotes, DNA can be loosely packed, allowing transcription, or tightly packed, rendering it inaccessible. This dynamic “on/off” switch is critical for development, cell specialization, and responses to environmental changes.
Evo 2 addresses this by combining with specialized models (like Enformer or Borzoi) that predict how open or closed a segment of DNA is likely to be. Researchers specify desired accessibility patterns, say, “open in positions X and Y, closed elsewhere.” Evo 2 then generates sequences, and the complementary model scores each proposal. Through iterative refinement, the system hones in on sequences that match the desired epigenomic profile.
Why is that important? Because being able to fine-tune which regions are epigenetically open or closed paves the way for advanced gene circuit engineering, where specific genes need to be turned on or off at precise times or in certain tissues. It’s a potent technology for areas like regenerative medicine or targeted cell therapies, where controlling gene expression is paramount.
Architectural Innovations
Evo 2’s architecture (covered in a preprint here) departs from traditional transformer models, opting instead for a multi-hybrid design that combines convolutional neural networks with attention mechanisms. This innovation, developed with input from OpenAI co-founder Greg Brockman, boasts significant efficiency improvements and overcomes the scaling limitations of transformer architectures.
The new architecture, called Striped Hyena 2, supports context windows of 1 million nucleotides, which is 8× larger than Evo 1 (released only in November 2024). This profound upgrade is a critical for understanding how distant regions of the genome interact.

Evo 2’s one million base pair context window enables genetic sequences up to the size of a yeast chromosome. (Credit: Arc Institute)
Training such a massive model required 2,048 NVIDIA H100 GPUs on the DGX Cloud platform, a collaboration facilitated by Amazon Web Services. For context, this is about 150x more compute than AlphaFold and around twice the number of FLOPS as Evolutionary Scale’s ESM3.
Expanding the Reach of Genomics and Personalized Medicine
With Evo 2’s capabilities in reading, interpreting, and designing DNA, the real-world applications are far-ranging:
- Clinical Variant Interpretation— Assess if a particular mutation in a patient’s genome might be pathogenic. Notably, coverage of both coding and noncoding regions is a boon for comprehensive genetic testing.
- Discovery of Novel Biology— Evo 2’s internal sense of coding or regulatory elements may shine light on hidden evolutionary relationships or newly discovered genes.
- Synthetic Biology and Biomanufacturing— Bring more of the development pipeline in-silico. Design suggestions from Evo 2 can be incorporated to reduce trial-and-error in the lab.
- Epigenome Editing— As genetic editing technologies such as CRISPR become more refined, researchers might one day program entire genomic architectures, with Evo 2 guiding the blueprint for minimal risk and maximal function.
An Open-Source Commitment
One standout aspect of the Evo 2 project is its commitment to open science. The authors have released not only the model weights (allowing researchers to run Evo 2 themselves) but also the sprawling 9-trillion-letter dataset and the underlying training code.
This transparency invites scrutiny, collaboration, and creative repurposing by the scientific community. It’s an especially meaningful gesture in a field often overshadowed by proprietary solutions and locked-down pipelines.
Researchers can access and fine tune Evo 2 using NVIDIA’s BioNeMo framework. Arc also have a browser tool here.
However, open release also poses ethical challenges. Models powerful enough to generate or analyze potentially dangerous genetic elements need careful risk assessment.
The Evo 2 authors took steps such as excluding human cell-infecting viral sequences to mitigate misuse scenarios. Even so, a call for ongoing vigilance and the development of responsible AI biosecurity protocols remains central to the project’s ethos.
Limitations and Ethical Considerations
While Evo 2 opens new frontiers in understanding and designing DNA, it faces clear limitations in its biological scope and practical application. For one, it is trained on a snapshot of known genomes, which even at trillions of bases barely scratches the surface of Earth’s genomic diversity. This means that unexpected genomic patterns or atypical organisms could pose challenges for Evo 2’s predictive power.
The model also struggles with describing or generating regions it explicitly excluded, such as aforementioned pathogenic viral sequences.
Ethically, the capacity to design large stretches of DNA demands ongoing discourse, particularly concerning synthetic biology and potential dual-use scenarios. Although the model’s training data exclude certain pathogenic information, future adaptations or advanced models could reintegrate or reconstruct these sequences.
The Bigger Picture
Ultimately, Evo 2 anchors a vision in which computational biology transcends the single-gene perspective. By leaning on AI’s pattern recognition at genome-wide scales, scientists may discover emergent rules governing evolution, adaptation, and gene regulation. As models like Evo 2 advance, they will further illuminate how living systems function as dynamic networks of genetic elements. It’s a perspective vital for tackling pressing challenges in medicine, ecology, and beyond.